Scrapy框架简介
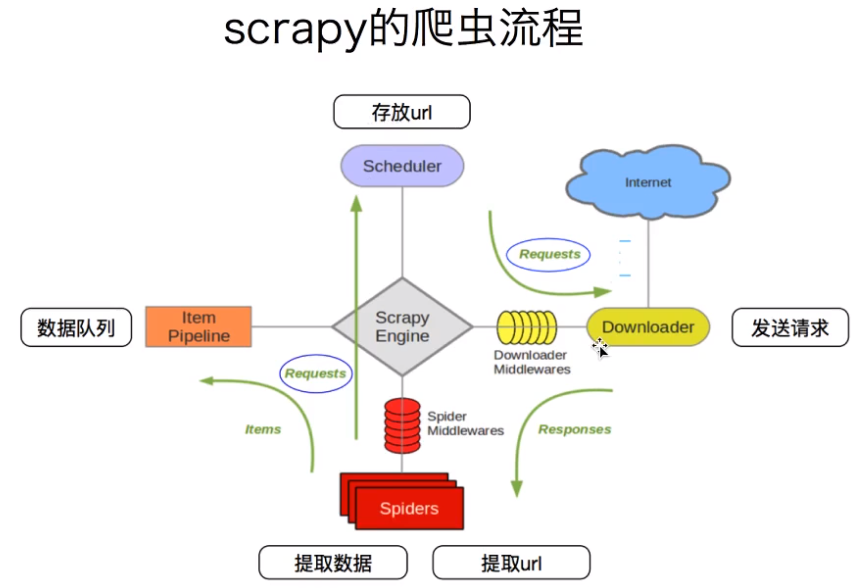

-Spider MiddlewaresSpider只对response进行过滤处理,不对数据进行处理
初始化
创建项目
1 | scrapy startproject myspider |
生成爬虫
1 | scrapy genspider response response.cn |
在生成的response.py文件中包含以下代码
1 | # -*- coding: utf-8 -*- |
运行爬虫
在项目文件夹下运行
1 | scrapy crawl response |
pipline
生成的item数据会传入pipline中,在使用pipline之前要先在settings.py中去掉
可以创建多个pipline:
1.可能有多个爬虫
2.可能爬取的数据需要不同的处理(如写入不同的数据库)
1 | class Test1Pipeline(object): |
如有多个pipline,每个pipline都要return item以传入下一个管道,不能缺少return
1 | #ITEM_PIPELINES = { |
的注释。
300表示举例pipline的远近,越小越先执行
若有多个爬虫,则可以
1.在item中加入item['come_from'] = 'spider1'
if item['come_from'] == 'spider1':
…
2.在pipline.py中直接用
if spider.name == 'spider1':
…
logging模块
logging模块是输出日志的模块
可以在settings.py中加入LOG_LEVEL = 'WARNING'来使程序输出warning及以上级别的日志
logging模块可以代替print输出数据并知晓数据来自哪一个文件
1 | import logging |
运行结果
1 | 2019-04-08 17:30:19 [test1.spiders.pixvi] WARNING: {'come_from': 'pixvi'} |
即可以打印输出内容的时间,文件来源,等级,内容
在settings.py中加入LOG_FILE = ./XXX.log即可把日志内容保存在文件中

