卷积神经网络
卷积核($w$)
通常遍历输入向量的所有通道,Input为32 X 32 X 3。
卷积核在输入的向量上滑动,至于图像的一个局部区域发生关联,进行点积运算$w^Tx+b $ $w为filter$
卷积核滑动
在图像空间滑动,计算出每个位置的点积(滑动的方式可以改变)
激活映射
PS
7X7X3 input(spatially)
assume 3X3X3 filter
可以得到一个5X5X1的output
有多少个卷积核则Output的深度为多少。
步长(stride)
控制滑动的步长可以得到不同的output。
如果stride=3则无法fitinput的纬度,则不采用。
Output size:
$(N-F) / stride + 1$
可以增加像素(PS:补0)来改变输出的维度,保持输出维度和输入维度相同。
Pooling layer
将生成的表示更加小以及更易于控制,是参数更少。
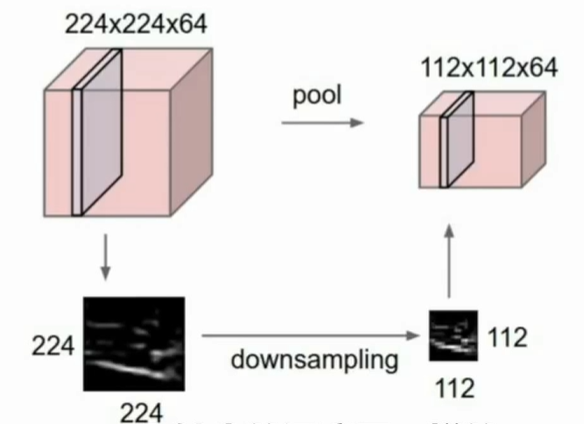
进行降采样(downsampling),只在平面上进行降采样,不在深度上降采样。
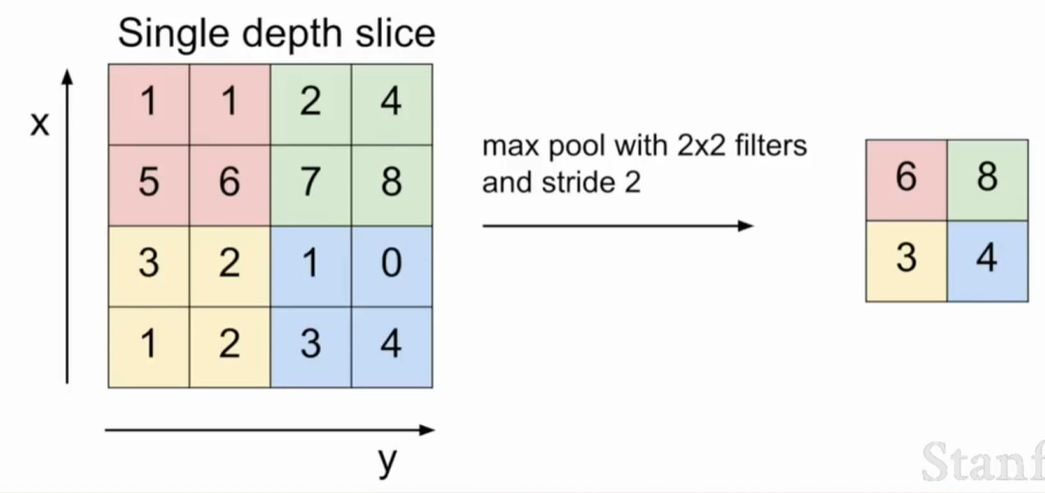
最大池化法(max pooling)
池化层中也有一个卷积核(卷积核和步长使扫描区域不重合),在滑动过程中不进行点积计算而是只取最大值。
最大值可以反映在这个区域内神经元受激程度,所以最大池化法比均值池化法用的更多。
一般在池化层不进行0像素填补
Common settings
F = 2, S = 2
F = 3, S = 3
一般的卷积神经网络结构
CONV + RELU + POOL + FC
激活函数
见note-2
数据预处理
一般对于图像,做零均值化的预处理(均值指所有输入图像的均值)
均值减法(Mean subtraction)是预处理最常用的形式。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。在numpy中,该操作可以通过代码X -= np.mean(X, axis=0)实现。而对于图像,更常用的是对所有像素都减去一个值,可以用X -= np.mean(X)实现,也可以在3个颜色通道上分别操作。
权重初始化
权重初始化太小会造成网络崩溃,权重太大网络饱和,导致梯度消失。
Xavier初始化
w = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
如果使用ReLU激活函数,会造成一半左右的神经元消失
在权重初始化的时候w = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in / 2)
批量归一化(Bathch Normalization)
起因:在高斯范围内激活,将数据变为单位高斯数据
批量归一化可以理解为在网络的每一层之前都做预处理,只是这种操作以另一种方式与网络集成在了一起
归一化公式
$k$代表输入的每个维度,分别对每一个维度独立计算经验均值和方差。
运用:通常在全连接层或者卷积层之后、非线性层(激活函数层)之前加入BN。
作用: 批量归一化使我们可以使用更高的学习率,而对初始化则不必那么小心 。
在完成归一化操作之后,还(需要)进行额外的缩放操作
可以学习$\gamma$和$\beta$以调整网络的饱和程度,若将其学习为均值和方差则可以完成于原数据的恒等映射。
总结

- 改进了整个网络的梯度流
- 有了更高的鲁棒性,允许使用更广范围的学习率和不同的初始化下进行学习
- 可以看作一种正则化方法
Babysitting the Learning Process
step1:数据预处理
step2:网络构造
step3:检验网络是否合理
step3:进行训练
神经网络优化
Fancier Optimization
SGD
SGD的问题
- 只对一个方向的敏感度高,会在不敏感的方向反复增减。
- 会找到局部极小值或者鞍点(梯度为零),在高维参数空间中,局部最小值不常见,常见的是鞍点。
- 随机性,因为SGD使用的是minibatch(=1),会产生噪声,如果在梯度下降时加入噪声会花费很长的时间
解决:
SGD+Momentum

在局部最优点或者鞍点时,梯度为0,但依旧会有一个速度,能够越过这个点继续进行梯度下降。
加入动量之后,噪声会被抵消,下降曲线更平滑。
Nesterov Momentum

AdaGrad&RMSProp
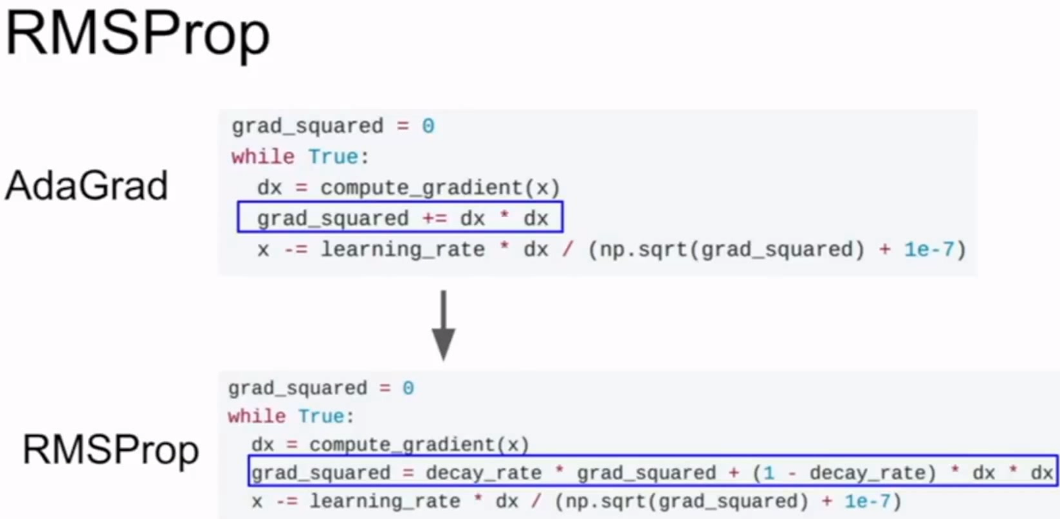
AdaGrad对于凸函数来说效果比较好,在接近极值点时会减小步长。
Adam
结合momentum&AdaGrad&RMSProp,加入第一动量和第二动量。
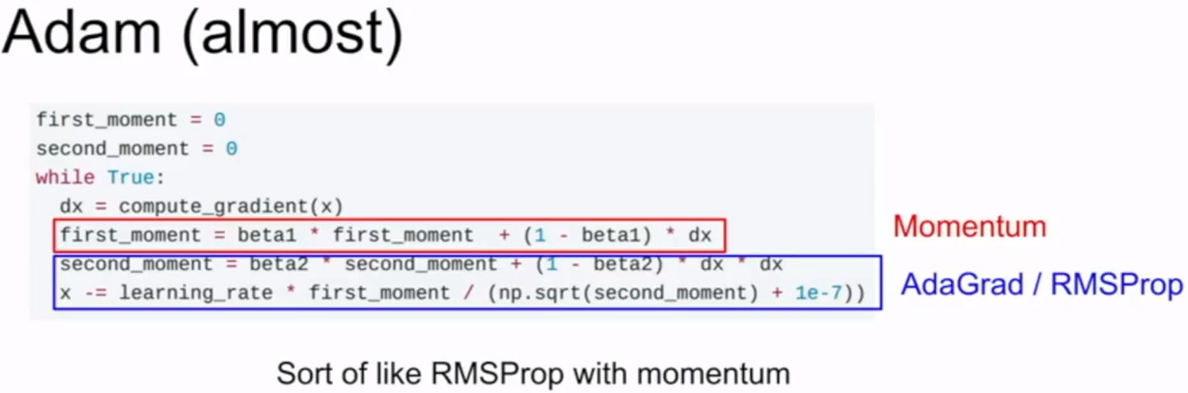
有可能first_moment以及second_moment趋于0,人为造成第一步步长很大。
改进:

beta1=0.9,beta2=0.999,lr=1e-3or5e-4 is a great initialization point for many models.
关于Learning Rate
Learning rate decacy over time
- 指数衰减
- 1/t衰减
ps:SGDlr衰减很常见,但是Adam优化lr衰减很少用
Second-Order Optimization(TODO)

牛顿法-拟牛顿法
正则化
Dropout
在正向传播时随机将一层中的节点置零()然后继续传播。
hyperparameter=0.5 is common
一般在全连接层使用Dropout,在卷积层中,可能是将某一通道全部置零。
- 避免了特征之间的联系/组合
- 可以看作model集成
在predict函数中不进行随机失活,但是对于两个隐层的输出都要乘以$p$,调整其数值范围。 最后输出的期望值为原输出*hyperparameter。
1 | p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱 |
Inverted dropout
1 | """ |
运用dropout可能会用更长的时间进行训练,但是在收敛之后,模型的鲁棒性会更好。
Batch Normalization
Data Augmentation
- transform image
- crops and scales
- Color Jitter(色彩抖动)
DropConnect
随即将权重的一些值置零。
Fractional Max Poolong(TODO)
在最大池化层进行部分随机池化。
Stochastic Depth(随即深度)
在训练中,随机丢弃一些层,只用部分层。
迁移学习
不需要超大的样本集
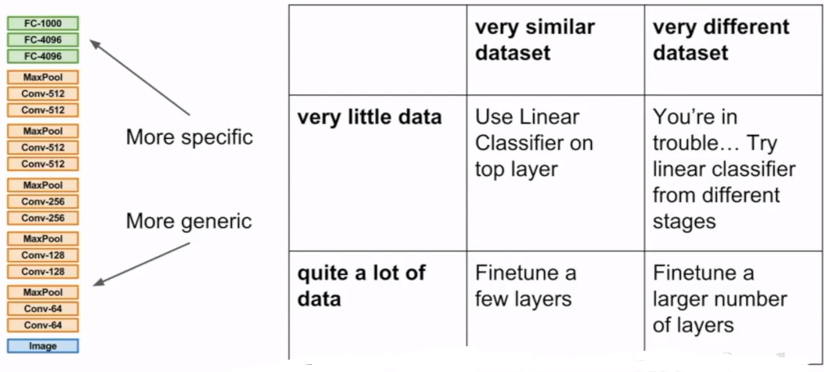
预训练模型


