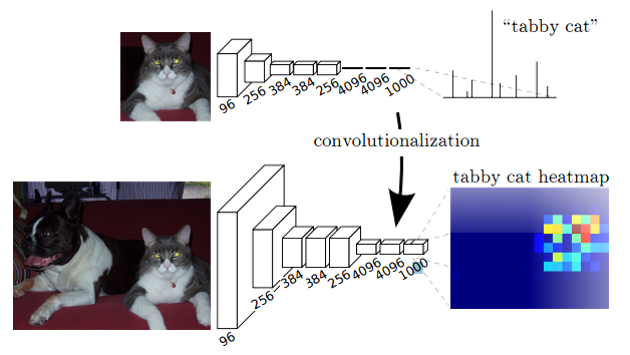
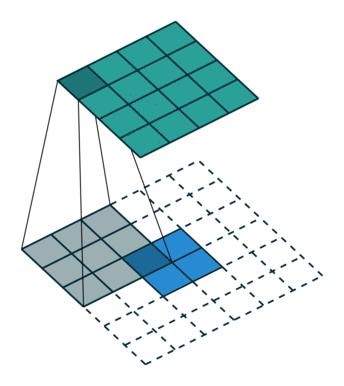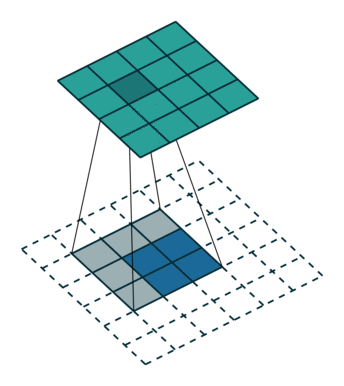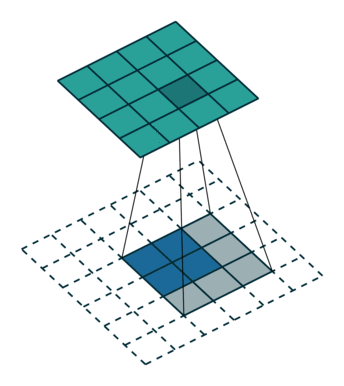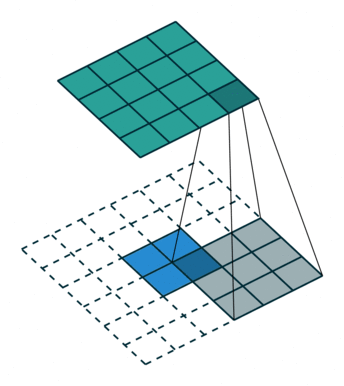
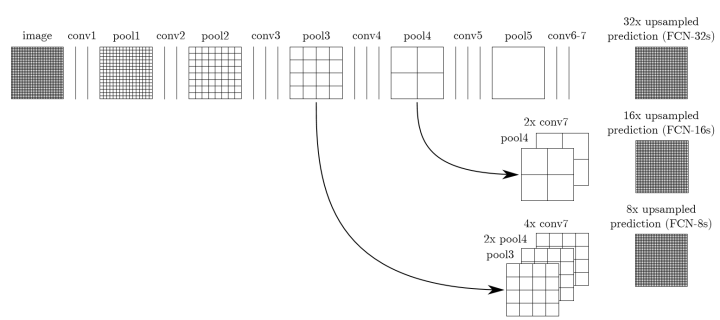
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| class FCN8s(nn.Module):
def __init__(self, num_classes, pretrained=True, caffe=False):
super(FCN8s, self).__init__()
vgg = models.vgg16()
if pretrained:
if caffe:
vgg.load_state_dict(torch.load(vgg16_caffe_path))
else:
vgg.load_state_dict(torch.load(vgg16_path))
features, classifier = list(vgg.features.children()), list(vgg.classifier.children())
'''
100 padding for 2 reasons:
1) support very small input size
2) allow cropping in order to match size of different layers' feature maps
Note that the cropped part corresponds to a part of the 100 padding
Spatial information of different layers' feature maps cannot be align exactly because of cropping, which is bad
'''
features[0].padding = (100, 100)
for f in features:
if 'MaxPool' in f.__class__.__name__:
f.ceil_mode = True
elif 'ReLU' in f.__class__.__name__:
f.inplace = True
self.features3 = nn.Sequential(*features[: 17])
self.features4 = nn.Sequential(*features[17: 24])
self.features5 = nn.Sequential(*features[24:])
self.score_pool3 = nn.Conv2d(256, num_classes, kernel_size=1)
self.score_pool4 = nn.Conv2d(512, num_classes, kernel_size=1)
self.score_pool3.weight.data.zero_()
self.score_pool3.bias.data.zero_()
self.score_pool4.weight.data.zero_()
self.score_pool4.bias.data.zero_()
fc6 = nn.Conv2d(512, 4096, kernel_size=7)
fc6.weight.data.copy_(classifier[0].weight.data.view(4096, 512, 7, 7))
fc6.bias.data.copy_(classifier[0].bias.data)
fc7 = nn.Conv2d(4096, 4096, kernel_size=1)
fc7.weight.data.copy_(classifier[3].weight.data.view(4096, 4096, 1, 1))
fc7.bias.data.copy_(classifier[3].bias.data)
score_fr = nn.Conv2d(4096, num_classes, kernel_size=1)
score_fr.weight.data.zero_()
score_fr.bias.data.zero_()
self.score_fr = nn.Sequential(
fc6, nn.ReLU(inplace=True), nn.Dropout(), fc7, nn.ReLU(inplace=True), nn.Dropout(), score_fr
)
self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, bias=False)
self.upscore_pool4 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, bias=False)
self.upscore8 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, bias=False)
self.upscore2.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 4))
self.upscore_pool4.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 4))
self.upscore8.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 16))
def forward(self, x):
x_size = x.size()
pool3 = self.features3(x)
pool4 = self.features4(pool3)
pool5 = self.features5(pool4)
score_fr = self.score_fr(pool5)
upscore2 = self.upscore2(score_fr)
score_pool4 = self.score_pool4(0.01 * pool4)
upscore_pool4 = self.upscore_pool4(score_pool4[:, :, 5: (5 + upscore2.size()[2]), 5: (5 + upscore2.size()[3])]
+ upscore2)
score_pool3 = self.score_pool3(0.0001 * pool3)
upscore8 = self.upscore8(score_pool3[:, :, 9: (9 + upscore_pool4.size()[2]), 9: (9 + upscore_pool4.size()[3])]
+ upscore_pool4)
return upscore8[:, :, 31: (31 + x_size[2]), 31: (31 + x_size[3])].contiguous()
|