Multimodal-Transformer
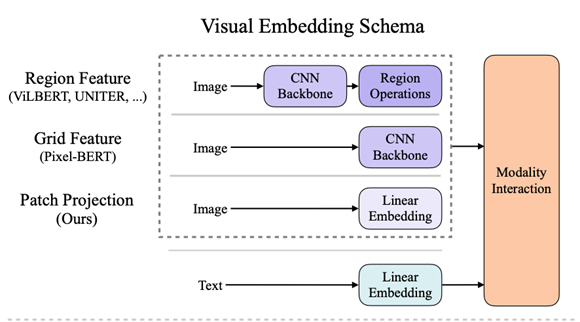
Visual Embedding Schema
图片来自ViLT
- Region Feature
利用faster rcnn提取bbox的region feature作为multimodel transformer的输入。
ViLBert|LXMERT|VL-BERT|VisualBert|Unicoder-VL|UNITER|VinVL
- Grid Feature
直接利用CNN backbone提取出的grid feature
- Patch Projection
类似VIT将输入的图像分成多个patch直接输入transformer
image:ViLT
video:TimeSformer|ViViT|VTN
由于Region Feature方法对于视频数据不是很友好,主要介绍Grid Feature方法和Patch Projection方法
Grid Feature
Pixel-Bert
pixel-bert提出是为了解决目前Region Feature方法的一些问题,这些方法只能提取到图片的部分目标的特征,对应的文本部分并不能完全和提取出来的特征相对应。

论文提出了pixel-text level语义对齐的end2end网络,可以有效的解决这个问题。
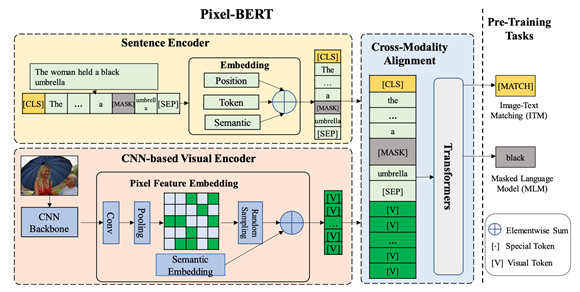
模型由三个部分 CNN-based visual Encoder 基于bert的Sentence Encoder以及Joint-Transformer
预训练有两个任务 MLM和ITM
文本部分
采用和Bert一样的处理方式 输出N个token
图像部分
提出了Pixel Feature Embedding,将图片过backbone然后平铺特征 ,k代表pixel的数量。然后对pixel特征加上一个区分于文字的semantic embedding作为transformer的输入。
在pre-train阶段,论文还提出Pixel Random Sampling的方法来对backbone提取到的pixel feature map进行随机采样,增强网络的鲁棒性减缓过拟合。(感觉是用部分的pixel来学习到完整的visual特征,增强表征能力)
多模态融合部分
将1和2的输出作为transformer的输入
训练细节
利用COCO和VG数据集合进行预训练,不同分支利用不同的优化器,visual backbone用SGD,transformer用AdamW。
CLIPBERT
官方代码:https://github.com/jayleicn/ClipBERT

传统的video-text模型采用的模式是固定vision/text的backbone提取两种模态的特征输入到融合模型。这种传统的模式会有两个缺点:
对不同任务/领域的数据集 feature提取器需要进行不同的预训练,才会有比较好的效果。
不同模态的feature之间有可能是割裂的,比如在视频动作识别模型是靠纯视频特征进行学习的,并没有用到文本特征。端到端的finetune会有效的解决这一点。
CLIPBERT借鉴了PixelBert中稀疏采样的方法,对视频的帧进行稀疏采样。在训练时将多个clip进行片段推理,最后将多个片段的推理结果合并作为整个视频总的结果。由于是稀疏采样视频帧进行训练,并且考虑到image-text预训练对video-text模型有一定的收益,模型采用2-D visual backbone提取视频特征,可以减小模型的计算量。

每个CLIP代表随机采样视频中的某一个片段
每个CLIP由该片段中随机采样T帧组成,将T帧的特征进行Fusion然后送入transformer,融合text特征。
相当于model的visual部分输入为(B, N, T, H, W, D),分别对应Batch_size,N个clip,每个clip包含T帧,图片被降采样为HxW,每帧图片过backbone得到D维特征。对降采样的特征做2D position embedding然后以(B, HxW, D)的token输入transformer。clip在我的理解是每个视频样本过N次模型得到N个结果,最后将N个结果进行融合然后传给video-level的下游任务。
代码实现中在训练时打包数据集以(B, T=num_clips*num_frm, C, H, W)的shape打包,在训练时将reshape成(B, num_clips, num_frm, C, H, W),然后分clip过model,组后将得出来的logits进行concat
Patch Projection
ViLT
code:https://github.com/dandelin/vilt
论文提出了一种基于类似VIT中的Patch Projection方法的更轻量的多模态Transformer,没有使用常见的CNN backbone(不管是检测器还是ResNet)。
基于CNN的模型有两个比较大的问题。一是计算量会很大,二是表征能力取决于视觉模型,以及预定义的视觉词汇(图像语义可能比文字表现得少很多)。
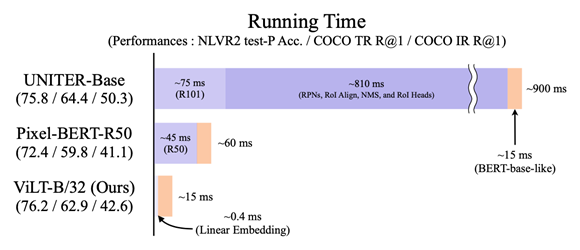
论文提出的方法直接将图像分为patch和文字一起直接输入transformer进行联合训练

训练细节
模型初始化为预训练的VIT,能够弥补没有图像特征提取的缺陷。
预训练任务为MLM和ITM,在预训练时,利用了whole word masking的方法,whole word masking是将连续的子词tokens进行mask的技巧,避免了只通过单词上下文进行预测。比如将“giraffe”词tokenized成3个部分[“gi”, “##raf”, “##fe”],可以mask成[“gi”, “[MASK]”, “##fe”],模型会通过mask的上下文信息[“gi”,“##fe”]来预测mask的“##raf”,就会导致不利用图像信息。这样可以最大化的利用视觉特征来补全语言特征。
在预训练时没有对图像做augmentation,在finetune时运用了除颜色改变和剪裁之外的random aug。
ViViT
关于video的pathch projection方法
整体上还是采取了VIT的思路
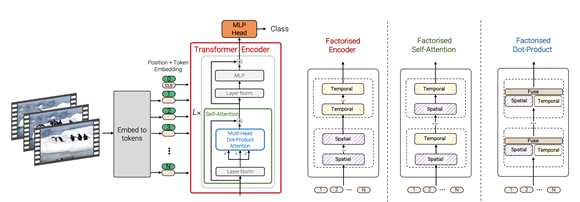
Embedding Video Clips
- Uniform frame sampling
这种方法均匀采样n帧图片,采用和VIT一样的处理方法,分别对单张图片进行分patch操作,类似于对一张巨大的图片进行操作
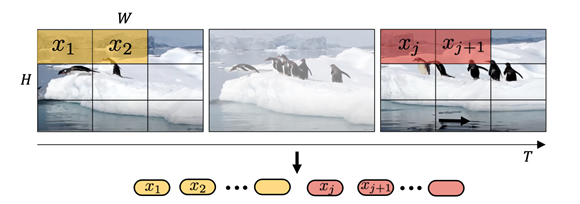
- Tubelet embedding
在时空两个维度进行采样,可以更好利用video的时序信息

Encoder 变体
由于随着视频帧数的增加,token数量是线性增加的,会带来很高的复杂度,所以论文中提出了一些模型的变体。
- Factorised Encoder
采用两阶段的transformer,第一阶段transformer对每帧的图片进行处理,然后把cls输出作为下一阶段transformer的输入,第二阶段的transformer融合时序信息。类似于late-fusion的思路。

PS:从FLOPs角度来看计算量是小于直接用全部token过transformer的
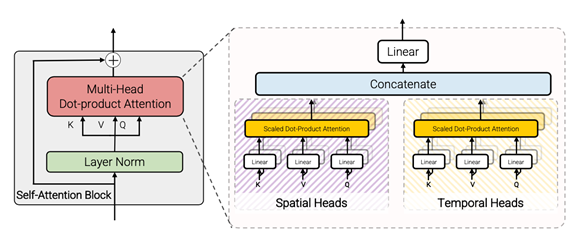
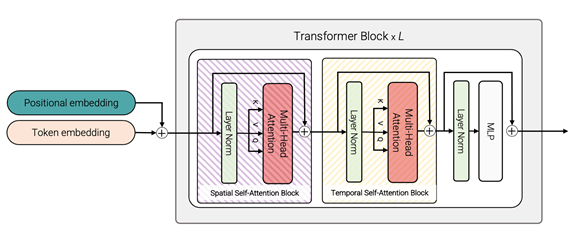
- Factorised self-attention
直接在一个transformer中对时间和空间分开计算self-attention
- Factorised dot-product attention
将一个self attentin分为spatial和temporal两部分,K,V分成两 ,然后将两组output concat得到最终的输出。